
[C++] 셋(set), 맵(map)
셋(set), 멀티셋(multiset), 맵(map), 멀티맵(multimap)은 이진 탐색 트리(BST)를 기반으로 하는 연관 컨테이너(associative container)임.
(정확히 말하면 Red-black-tree. 스스로 균형을 맞추는 bst라고 생각)
따라서 vector,list,deque같은 시퀀스 컨테이너들과 비교했을때, 트리구조가 갖는 장점을 그대로 가져감.
셋 ( set )
- 자동으로 정렬됨
- 중복된 원소 없음(중복된 원소를 허락하고 싶다면 multiset 사용)
데이터의 존재 유무를 판별할 때 사용함.
#include <set> //헤더 파일
std::set<int> s; //set 정의
s.insert(10); //set에 키값 추가
//set에 해당 키가 있는지 확인하는 방법
auto itr = s.find(20);
if (itr != s.end())
{
std::cout << "Yes" << std::endl;
}
else
{
std::cout << "No" << std::endl;
}
//set 순회
for (set<int>::iterator iter = s.begin(); iter != s.end(); iter++)
{
cout << *iter;
}
for (auto iter : s)
{
cout << iter;
}
셋에 원소를 추가하거나 지우는 작업은 O(log N) 임.
범위기반 for문또한 사용 가능하며, 원소들의 접근 순서는 반복자를 이용해서 접근했을때와 동일함.
멀티셋 ( multiset )
셋에서 중복된 원소를 허락한 버전.
std::multiset<std::string> s;
s.insert("a");
s.insert("b");
s.insert("a");
s.insert("c");
s.insert("d");
s.insert("c");
print_set(s);
/*출력결과
a
a
b
c
c
d
*/
기존 set이라면 a,b,c,d 이렇게 출력됐을 것임.
맵 ( map )
-
자동으로 정렬됨
-
중복된 key 없음(중복된 key를 허락하고 싶다면 multimap 사용)
맵은 셋과 거의 동일하지만 셋은 key만 보관하지만, 맵은 key-value를 보관함.
map<string,int> student_score;
student_score.insert(std::pair<std::string,int>("김남제",50));
student_score.insert(std::make_pair("엄준식", 100));
student_score["찬우정"]=60;
첫번째로 입력하는 타입은 key의 타입이고, 두번째는 value의 타입.
위 세가지 방법으로 key-value의 추가가 가능.
[ ]연산자의 경우, 만일 해당하는 키가 맵에 없다면 추가될 것이고, 있다면 value값이 바뀜.
insert는 이미 해당하는 키가 있다면 새로운 value로 대체하지 않고 무시함.
template <typename K, typename V>
void print_map(std::map<K, V>& m)
{
// 맵의 모든 원소들을 출력하기
for (auto itr = m.begin(); itr != m.end(); ++itr)
{
std::cout << itr->first << " " << itr->second << std::endl;
}
}
template <typename K, typename V>
void print_map(std::map<K, V>& m)
{
// kv 에는 맵의 key 와 value 가 std::pair 로 들어갑니다.
for (const auto& kv : m)
{
std::cout << kv.first << " " << kv.second << std::endl;
}
}
셋의 경우 *itr가 저장된 원소를 바로 가리켰지만, 맵은 반복자가 맵에 저장되어 있는 std::pair를 가리킴.
따라서 itr->first로 해당 원소의 키를, itr->second로는 해당 원소의 값을 알 수 있음.
범위기반 for문을 사용하면 std::pair값을 받아와서 위처럼 사용가능.
주의할 점
map<string,int> student_score;
student_score.insert(std::pair<std::string,int>("김남제",50));
std::cout<<"엄준식의 성적은? "<<student_score["엄준식"];
//출력: 0
위처럼 엄준식은 map에 key로 없지만, 위처럼 사용하게되면 자동으로 값의 디폴트 생성자를 호출해서 원소를 추가해버립니다. 따라서 안전한 사용을 위해서는 find 함수를 통해 확인 후 사용하는것이 좋습니다.
멀티맵 ( multimap )
맵에서 중복된 원소를 허락하는 버전임.
template <typename K, typename V>
void print_map(const std::multimap<K, V>& m)
{
// 맵의 모든 원소들을 출력하기
for (const auto& kv : m)
{
std::cout << kv.first << " " << kv.second << std::endl;
}
}
std::multimap<int, std::string> m;
m.insert(std::make_pair(1, "hello"));
m.insert(std::make_pair(1, "hi"));
m.insert(std::make_pair(1, "ahihi"));
m.insert(std::make_pair(2, "bye"));
m.insert(std::make_pair(2, "baba"));
print_map(m);
std::cout << "--------------------" << std::endl;
// 1 을 키로 가지는 반복자들의 시작과 끝을
// std::pair 로 만들어서 리턴한다.
auto range = m.equal_range(1);
for (auto itr = range.first; itr != range.second; ++itr)
{
std::cout << itr->first << " : " << itr->second << " " << std::endl;
}
/*출력 결과
1 hello
1 hi
1 ahihi
2 bye
2 baba
--------------------
1 : hello
1 : hi
1 : ahihi
*/
unordered_set과 unordered_map
셋,맵은 bst를 이용하기 때문에, 어쩔수없이 정렬이 되는데, 이 오버헤드를 없애고자 나온 것이
unordered_set과 unordered_map임.
unordered_set과 unordered_map은 bst가 아닌, 해시맵을 사용하기 때문에 insert,erase,find 모두가 O(1) (보통의 경우)로 수행됨.
(그래서 사실 hashset, hashmap이란 이름이 어울리지만 이러한 이름을 너무 많이 쓰고 있어서 충돌을 피하려고 위와같은 이름으로 했다고 함.)
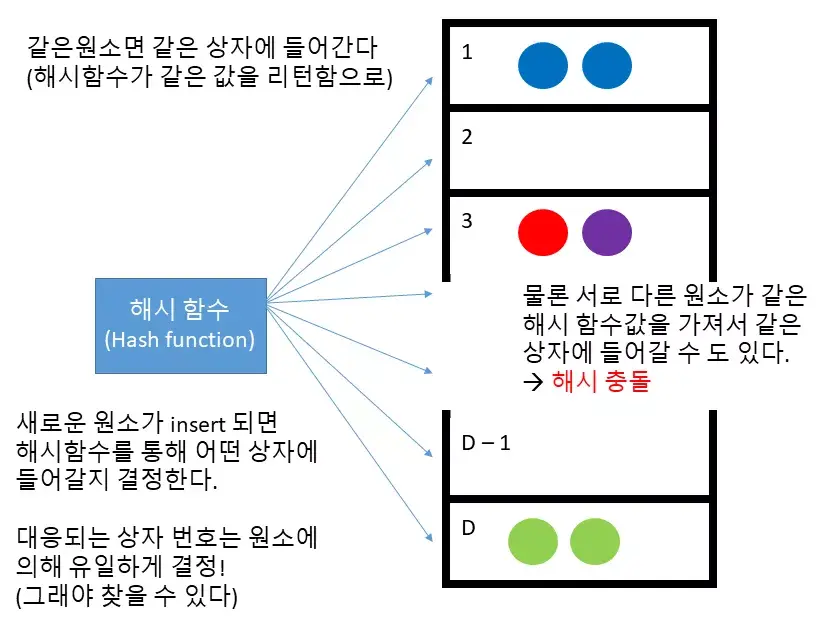
해시 함수란 임의의 크기의 데이터를 고정된 크기의 데이터로 대응시켜주는 함수라고 볼 수 있음.
이 때 보통 고정된 크기의 데이터라고 하면 일정 범위의 정수값을 의미함.
해시 함수의 가장 중요한 성질은, 만약에 같은 원소를 해시 함수에 전달한다면 같은 해시값을 리턴한다는 점임.
이 덕분에 원소의 탐색을 빠르게 수행할 수 있음.
빨간색 공과 보라색 공 처럼 다른 원소임에도 불구하고 같은 해시값을 갖는 경우가 있을 것임.
이를 해시 충돌(hash collision) 이라고 하는데, 이 경우 같은 상자에 다른 원소들이 들어있게 됨.
따라서 만약에 보라색 공이 이 셋에 포함되어 있는지 확인하고 싶다면 먼저 보라색 공의 해시값을 계산 한 뒤에, 해당하는 상자에 있는 모든 원소들을 탐색해보아야 할 것임.
운이 매우 매우 나쁘다면 다른 색들의 공이 모두 1 번 상자에 들어갈 수 도 있음.
이 경우 탐색이 O(1)O(1) 은 커녕 O(N)O(N) (여기서 n 은 상자의 개수가 아니라 원소의 개수) 으로 실행될 것임.
처음부터 많은 개수의 상자를 사용할 수 없기 때문에 (메모리를 낭비할 순 없으므로..) 상자의 개수는 삽입되는 원소가 많아짐에 따라 점진적으로 늘어나게 됨.
문제는 상자의 개수가 늘어나면 해시 함수를 바꿔야 하기 때문에 (더 많은 값들을 해시값으로 반환할 수 있도록) 모든 원소들을 처음부터 끝 까지 다시 insert 해야 함. 이를 rehash 라 하며 O(N) 만큼의 시간이 걸립니다.
기본 타입들(int, double 등등) 과 std::string 의 경우 라이브러리 자체적으로 해시 함수가 내장되어 있으므로, 그냥 사용해도 됨.
그러나 직접 만든 클래스의 경우 해쉬함수를 직접 만들어줘야 함. 그리고 셋이나 맵과는 다르게 순서대로 정렬하지 않기 때문에 operator< 는 필요하지 않지만 hash collision시 상자 안에 있는 원소들과 비교를 해야하기 때문에 operator==는 필요함…
(자세한 것은https://modoocode.com/224 이곳과 https://woo-dev.tistory.com/106 이곳 참고)
댓글남기기